State of DataHaskell Q1 2026
As the new year gets into swing and the holiday slump wears off we figured it would be a good time to take stock of things: share what we’ve learned, what we shipped, and what we’re focusing on next.
We’ll be using this as input for our monthly community meeting: Saturday, January 17th, 2026 at 9AM PST.
Summary
- We did a listening sprint. We talked to a bunch of people who’ve shaped the Haskell ecosystem to understand what’s missing and what’s realistic.
- Community + ecosystem friction is the bottleneck. “Time to first plot” and “time to first successful notebook” matter more than any single library.
- People want low-friction ways to help. Feedback, docs, tutorials, and well-scoped fixes beat “please become a maintainer.”
- Our near-term focus: tighten onboarding, publish bite-sized contribution tasks, and get DataHaskell into a small number of real workflows.
- We’re looking for pilot partners. If your team uses Haskell and has data work you’d like to improve, we’d love to talk.
What is DataHaskell in 2026?
DataHaskell is an effort to make Haskell a practical option for day-to-day data work. We’d like to emphasise the things Haskell is unusually good at: composition, correctness, and building tools you can reason about.
There are, broadly speaking, two directions the ecosystem could go:
- Parity with Python/R - a type-safe alternative that tries to cover the same workflows and libraries.
- Lean into Haskell’s strengths - carve out a niche where Haskell’s advantages are obvious.
We’re trying to balance both, but we’re leaning toward the second.
Our current bet: symbolic AI tooling for tabular data
When we say symbolic AI tooling, we mean tools that help you build and simplify interpretable models by searching over programs - not just fitting opaque parameters.
Concretely, that includes things like: feature synthesis (automatically generating small, meaningful features from raw columns with constraints), interpretable model search (generating compact decision rules / trees / expressions that you can inspect, diff, and export), program optimization (simplifying or rewriting model expressions safely e.g., removing dead branches, canonicalizing expressions, enforcing constraints like monotonicity).
This is an area where Haskell’s strengths (typed DSLs, algebraic modelling, compositionality) can shine without trying to replicate the entire Python ecosystem overnight.
Listening sprint
Our work last quarter began with a lot of interviews. We fished out as many names as we could that could help give us context on how far the ecosystem has come and where they think it should go (all the while resisting the urge to turn it into a podcast). So firstly, special thanks to everyone that’s taken the time to speak to us over the last few months. In particular: Sam Stites, Laurent P. René de Cotret, Ed Kmett, Michael Snoyman, Bryan O’Sullivan, Tom Nielsen, and Aleksey Khudyakov.
What we learnt
Community and ecosystem are the hard problems. For DataHaskell to succeed a number of factors (and people) must work in unison to make a single clear vision happen. Very few people will touch the ecosystem unless they can read their favourite data format, or plot their results, or run machine learning models easily, or have everything work in Jupyter. We need a pool of contributors and users to guide the overall roadmap.
Growth and Participation
Naturally, our first concern was making sure we could tap into would-be-users and would-be-contributors in the Haskell community. After publicly announcing the revival of DataHaskell we got a surge of joins in our Discord server.
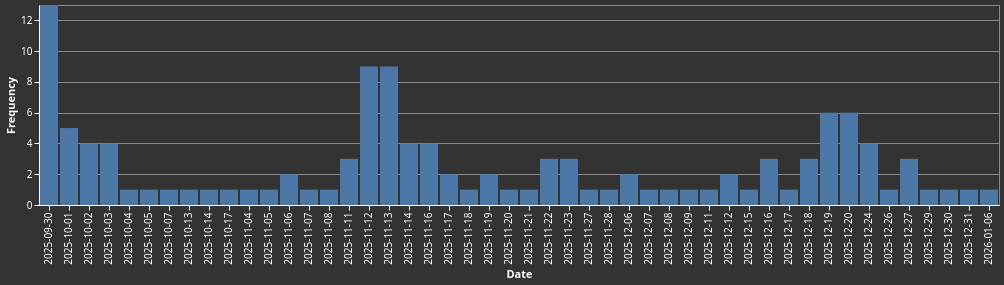
One of the first things we ask people to do after joining the Discord is to fill out an introductory survey. Of the 110 members of the Discord channel 31 have responded.
-
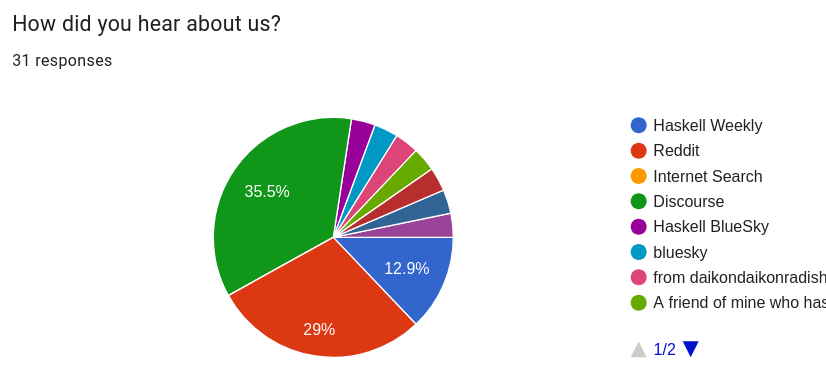
How did you hear about us?
-
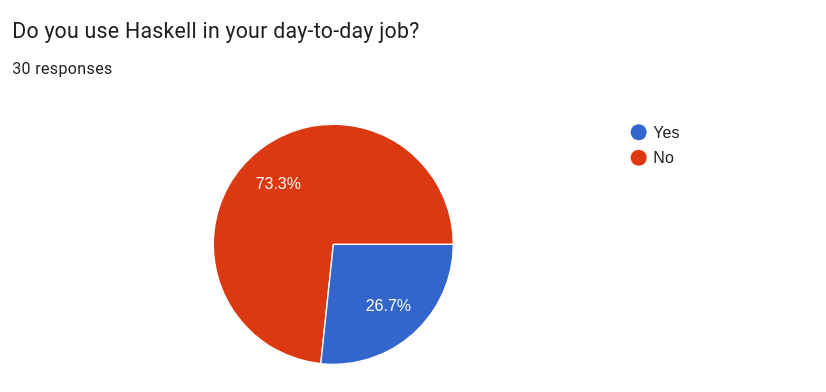
Do you use Haskell in your day-to-day job?
-
Which of these best describes your role?

-
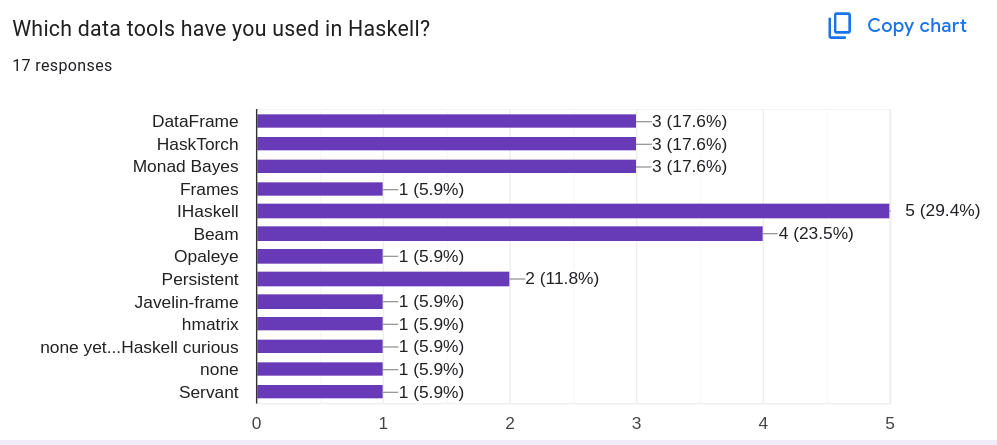
Which data tools have you used in Haskell?
-
How are you willing to contribute?
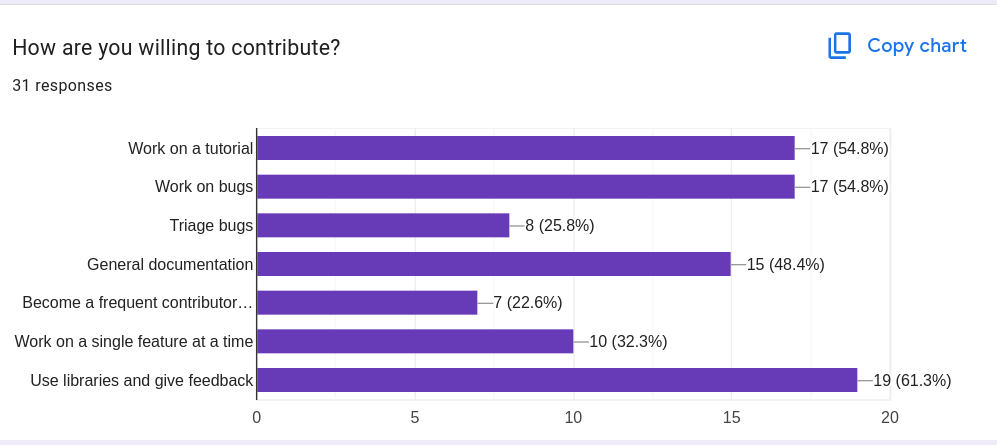
The survey suggests that people overwhelmingly want low-friction, bite-sized ways to help: trying the library and giving feedback, plus concrete, self-contained contributions like tutorials, docs, and bug fixes. Far fewer people are signalling “make me a long-term, ongoing maintainer.” The community is leaning toward many casual/occasional contributors rather than a small set of frequent ones.
Based on what we’re seeing, our outreach this year will optimise for:
- Fast feedback loops
- Regular “try this workflow” prompts (with a short form for structured feedback)
- Clear places to report friction (install issues, notebook issues, docs gaps)
- Beginner-friendly contribution work
- A steady stream of small, well-scoped issues
- Docs/tutorial tasks with clear definitions of done
- “30-minute tasks” that don’t require deep ecosystem knowledge
We’re actively partnering with maintainers (or contributors) in the following areas to scope out beginner-friendly tasks: IHaskell, Streamly, cassava, statistics/mwc-random, and HVega.
At the same time, we’re trying to identify longer-term contributors for these libraries because the ecosystem needs more shared ownership to grow.
Engaging the broader data science community
We’ve also reached out to people outside of the Haskell community. Designing tools for data science means solving problems for data scientists. We welcomed Jonathan Carroll as a core community member. Jonathan is a data scientist and a prominent member of the R community. He has been instrumental in guiding design and prioritisation decisions. We worked with Jonathan to write the article Haskell IS a Great Language for Data Science which showcased how Haskell features could make common tasks in data science easier and safer. We are currently working with Jonathan on a book called Haskell for Data Science which we expect will be available mid-to-early next year.
Technical contributions
Onboarding
We also spent the last few months addressing some persistent technical problems. One of the biggest hurdles users (new and current) face when working with Haskell is installing and managing the toolchain (compiler, package manager, and libraries). GHCup has made this story significantly better but the general ecosystem still has some rough edges (everyone has a failed IHaskell installation story). We specifically wanted to reduce “time to first plot” (a commonly talked about metric in the Julia community). While it’s tempting to funnel everyone to Nix we wanted to make sure the setup proposed as few new things as possible. To this end, we created a DataHaskell devcontainer and set it as the blessed path.
Tech debt and documentation
We’ve worked around the community to address several pain points: improving the installation experience of Hasktorch, resolving a decade-old feature request to create a poisson sampler, updating the IHaskell installation instructions, among other things. Again, for any single use case to succeed, the whole ecosystem must succeed too. Engagement has been fairly low in the Discord so it’s been difficult to figure out how to mobilise our members for these sorts of tasks. We’ll be trying a variety of outreach mechanisms throughout the year to encourage technical contributions.
Rethinking the roadmap
Our roadmap is ambitious, and we’re committed to seeing it through. But it isn’t rigid. We want it to reflect real user needs, not just our own excitement.
Top priorities for 2026
First, we want onboarding to feel boring in the best sense of the word. That means reducing setup friction, tightening the “blessed path,” and making “time to first plot” consistently short and reliable.
Second, we want to publish a small set of end-to-end workflows that actually reflect how people use data tools. These “golden paths” should show how DataHaskell fits together across ingestion, transformation, visualisation, and modelling - while also being honest about where the gaps are today. The point isn’t to cover everything; it’s to make a few workflows feel complete and repeatable.
Third, we want to build a real contribution funnel. Instead of undirected calls for help, we’ll maintain a visible, regularly updated board of bite-sized tasks and well-scoped docs/tutorial bounties. The intent is to make it easy for someone to contribute in an hour, feel useful immediately, and know what to do next if they want to keep going.
Fourth, we want notebook ergonomics to improve noticeably. That means better defaults, clearer installation and troubleshooting docs, and fewer ways for IHaskell to fail silently or get stuck in confusing states. For many people, notebooks are the front door so we want that door to open smoothly.
Finally, we want to pilot DataHaskell with one or two real teams using Haskell in production. The goal is to pick concrete workflows, ship fixes quickly, and let real pain points shape priorities. If we can make a small number of real users successful end-to-end, the roadmap gets sharper and the ecosystem work becomes much easier to justify and coordinate. If your company uses Haskell in production (or wants to), we’d love to work with you as a pilot partner in 2026. We’re looking for 1-2 teams where we can collaborate closely, ship improvements quickly, and learn what actually matters in day-to-day use.
Who are we?
The primary leads of DataHaskell are Michael Chavinda (mchav) and Jireh Tan (daikonradish). We prepared “Hello World” bios to formally introduce ourselves to the community:
I’m Michael Chavinda. I’ve spent most of the last decade building fraud detection systems and doing ML with tabular data (mostly at Google, and more recently at FIS Global). I’ve been writing Haskell on and off since 2015, and I keep coming back to it because a lot of industry problems line up well with functional programming ideas. You can see it in things like MapReduce and JAX: the ideas work at scale. With DataHaskell, I’m trying to help make Haskell a real option for day-to-day data work. Not just a cool idea. A toolkit people actually reach for.
I’m Jireh Tan, a data scientist focused on statistical and mathematical programming. I’ve worked at Facebook and Gojek. I contribute to DataHaskell because I believe that you should leave any environment 10% better than when you entered it. I enjoy writing Haskell because it looks so beautiful when it is written by an artisan, and many artisans have touched the libraries affiliated with DataHaskell.
Contributors: Michael Chavinda, Jireh Tan